The CityLearn Challenge 2020
Note
The CityLearn Challenge 2020 has now concluded!
Note
The CityLearn Challenge 2020 [24] used The CityLearn Challenge 2020 dataset [26] and CityLearn v1.0.0. To install this CityLearn version, run:
git clone -b v1.0.0 https://github.com/intelligent-environments-lab/CityLearn.git
Objective
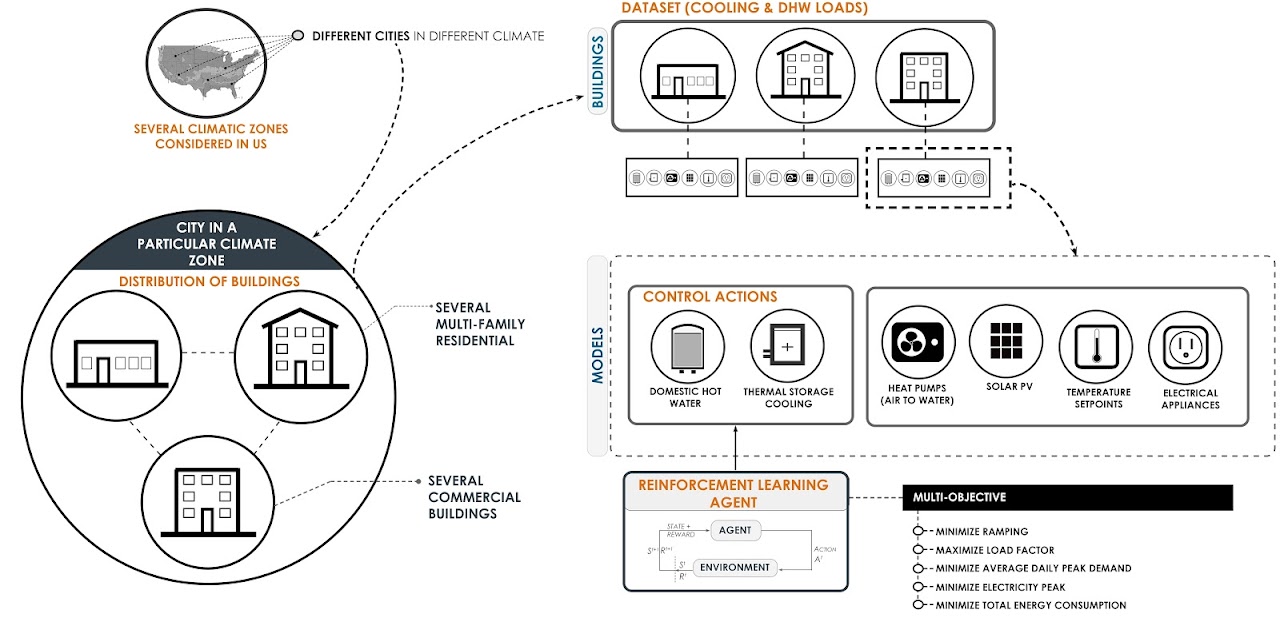
The objective of the challenge is to explore the potential of reinforcement learning as a control approach for building energy coordination and demand response [24]. In particular, participants will design, tune, and pre-train one central, or multiple decentralized, RL agents that minimize a multi-objective cost function of 5 equally weighted metrics in an entire district of buildings:
Peak demand (for the entire simulated period)
Average daily peak demand (daily peak demand of the district averaged over a year)
Ramping
1 - Load factor (which will tend to 0 as the load factor approaches 1)
Net electricity consumption
This multi-objective cost function is normalized by a baseline cost obtained from the performance of a rule-based-controller (RBC) tuned by hand. Therefore, RL_cost < 1 means that the RL agent performs better than a simple RBC.
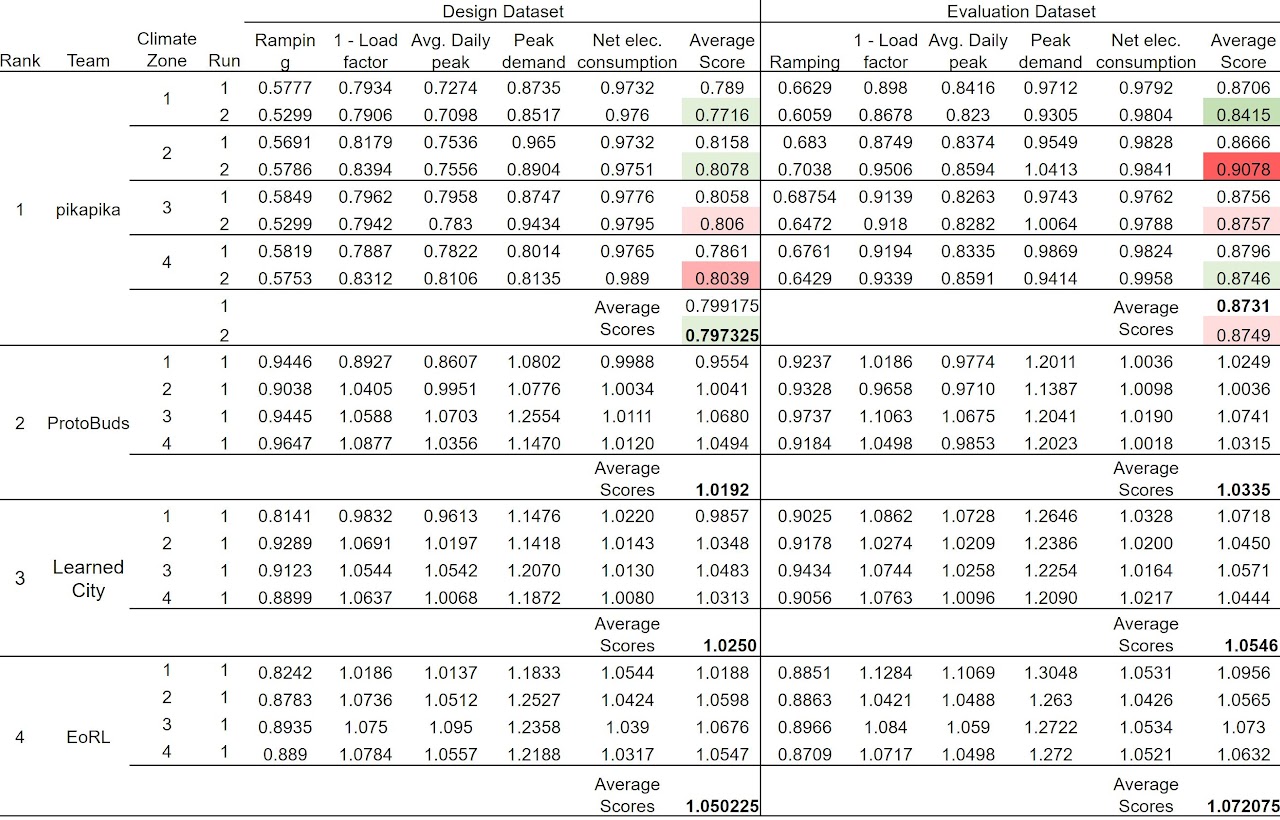
To analyze the plug-and-play and adaptive potential of RL, the controllers will be evaluated on a different dataset than the one that will be shared for the design, tuning, and pre-training of the controllers.
Rules and Instructions of the Challenge
Participants were provided with a design data set comprised of four sets of data from nine buildings each. Each set will have been simulated in one of four anonymous climate zones in the US. The dataset contained year-long hourly information about the cooling and DHW demand of the building, electricity consumed by appliances, solar power generation, as well as weather data and other variables. The design dataset were made available in the CityLearn GitHub repository after January 15th 2020, teams could sign up anytime before of after that date.
Participants used the design dataset to design, tune, and pre-train their RL controller(s) with the objective of shaping the load in the district and minimize the multi-objective cost function of the environment. Participants could select the states and actions the RL agents will use in each building in the file buildings_state_action_space.json, and could define their own reward function by modifying the file reward_function.py. Communication among buildings were allowed and must be coded within the file agent.py. Both centralized, and distributed controllers were allowed, and agents can take decisions both sequentially or simultaneously as long as it was all coded within the file agent.py. The file agent.py could call another file, to be made by the participants, which can contain the parameters of the pre-trained RL controllers. In the Github repository we provided a sample RL agent under the class RL_Agents, which had not been tuned or pre-trained but was only provided as an example.
Participants submitted their files agent.py, reward_function.py, buildings_state_action_space.json, and any file with the parameters of the pre-trained agents for their evaluation on an evaluation dataset, which were comprised of different buildings in the same climate zones but different cities. Participants received a score and the leader board was updated.
At the challenge stage, participants submitted their agents and reward function for the final run on the challenge dataset, which was different than the design and the evaluation datasets.
In the evaluation and challenge stages we will paste the files submitted (agent.py, reward_function.py, buildings_state_action_space.json, and file with pre-trained policies, weights, or other parameters) to the CityLearn folder, and run the file main.py` as it is. Therefore, it is important that any RL agents be coded within the class RL_Agents in the agent.py file.
Submission
The RL agents must be written in Python 3 and can use PyTorch or TensorFlow, as well as any other library that is already used in our GitHub repository. It must be able to run in both Windows and Linux OS, in either GPU (not necessary) or CPU (if GPU is not used or is not available). Files will be submitted by email to citylearn@utexas.edu under the subject “Submission StageOfChallenge Team_name”, where the StageOfChallenge can be “Evaluation Stage” or “Challenge Stage”.
At the evaluation and challenge stages, the agents will be simulated on a single one-year episode for buildings in four different climates, and the obtained costs are averaged to provide the final cost and update the leaderboard. Therefore, participants are encouraged to submit agents that have been pre-trained enough to perform well at the exploration phase but that are still able to learn from and adapt to the new buildings and weather conditions.
Some basic information about the characteristics of the buildings is provided to the agents in the file main.py using the CityLearn method get_building_information(). This method provides information about the type of building, climate zone, solar power capacity, total DHW, cooling, and non-shiftable energy consumption, and about the correlations of the demand profiles with the rest of the buildings. The agent(s) in the file agent.py are not allowed to read any of the files in the folder data.
Team Members
Each team can consist of maximum three members. The sign up link is here.
Submission Deadlines
Please see the timeline below for the detailed timeline of the three stages of the challenge.
Timeline

Stages of the Challenge
The challenge consisted of three stages:
Design Stage: The participants received four sets of building data and models in 4 anonymized climate zones. Each set contained data from 9 different buildings. The participants designed, tuned and trained RL agents at their convenience and modified the files:
agent.py,buildings_state_action_space.json, andreward_function.py. A third optional file can be created and submitted with weights and policies to be read by theagent.pyfile.Evaluation Stage: The participants submitted their trained agents which are run by the organizers on the evaluation set. The evaluation set consists of four sets of building data and models in 4 anonymized climate zones. Each set will contain data from 9 different buildings. The participants’ agents were tested on this evaluation set and the leaderboard is updated within a week of the submitted agent.
Challenge Stage: This is the final stage of the competition where the participants submitted their final agent(s). The agent was tested on the challenge set which consists of four sets of building data and models in 4 anonymized climate zones. Each set contained data from 9 different buildings. The participants received scores and the leaderboard was updated for the final time revealing the top scorers in the challenge.
Leaderboard
The leader-board displays the score of the individual participant’s agents within less than one week of the participant’s submission. This will provide the participants feedback about how their agent is performing compared to other participants in the challenge. The participants can improve and re-submit their agents as many times as they want within the Evaluation Stage. This cycle of submission and score update will continue till the time frame of the evaluation stage which continues till the end of June 12th AoE. The final deadline for the submission of the agents to be run on the challenge data set is the end of June 21st AoE.
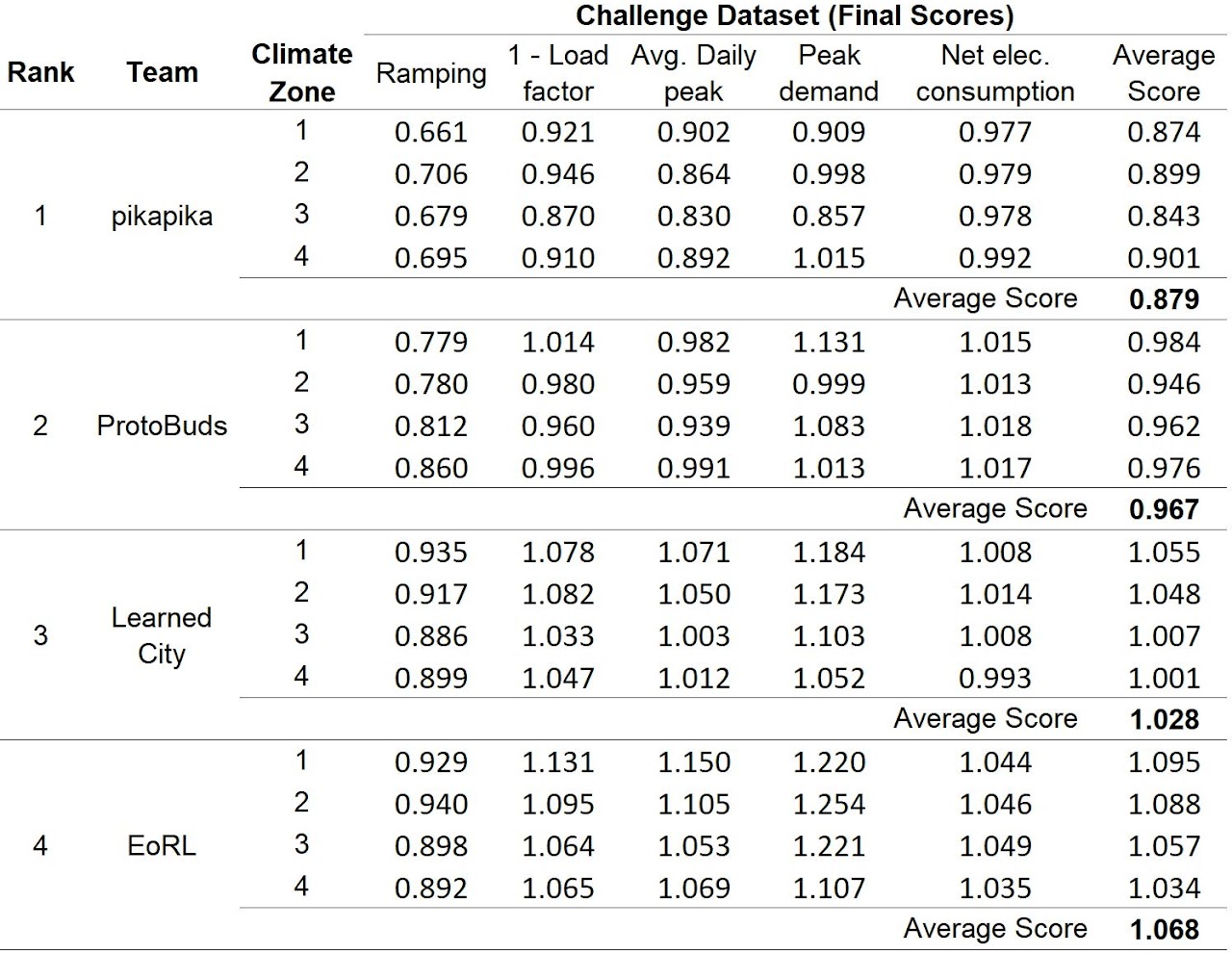
The scores of the leaderboard represent how well the reinforcement learning controller performs with respect to the baseline rule-based controller (RBC), i.e. a score of 0.9 indicates a performance 10% better than the RBC.
We congratulate the winning team, PikaPika, formed by Jie Fu, Bingchan Zhao, and Hao Dong from Mila (Polytechnique Montréal), and Peking University, who achieved a final score on the challenge set of 0.879!!
Team Name |
Affiliation |
Members |
Final Score (Lower is better) |
|---|---|---|---|
PikaPika |
Mila, Polytechnique Montréal; Peking University |
Bingchan Zhao, Jie Fu, Hao Dong |
0.879 |
ProtoBuds |
University College Dublin |
Anjukan Kathirgamanathan, Kacper Twardowski |
0.967 |
Learned City |
RWTH Aachen |
Vinay K.R. Bheemreddy, Thomas Schreiber, Stephen Alexander |
1.028 |
EoRL |
Freie Universität Berlin |
Filip Tolovski |
1.068 |